
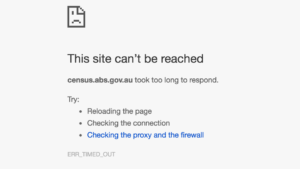
 Well, I think its safe to call the result of this year’s Australian census, making it a much quicker call than our Federal election last month – the results are in, and the ABS lost. Lost to the point that makes the Australian cricket team’s recent performance against Sri Lanka look not all that bad in comparison.
Well, I think its safe to call the result of this year’s Australian census, making it a much quicker call than our Federal election last month – the results are in, and the ABS lost. Lost to the point that makes the Australian cricket team’s recent performance against Sri Lanka look not all that bad in comparison.
It was, on pretty much all fronts, a train wreck.
A quick scan of the #censusfail hashtag on Twitter returns a barrage of criticism of the ABS, the Guvmint, and probably above all, of the underpinning technology platform used. While the technology is undeniably the thing which has broken tonight, I’d argue that it was the things that went on around the technology which were catalysts for the massive fail that was the night of August 9 for many of us (me included).
I say this with a sense of kinship after having opened the Flinders Connect service earlier this year. Granted, the demand was a lot smaller, and the resources on offer in our case were just as much people and place as technology, but the challenge was the same – introduce a new model for an existing need in a context where the demand is by its very nature highly ‘bursty’.
When I was planning Flinders Connect, one thing I didn’t have a lot of was data on how much traffic we could expect during peak times – there had been no consistent method of tracking demand prior to the introduction of Flinders Connect, so the best I could do was some rather ‘creative’ mathematical modelling, combined with (highly variable) benchmarking from other Universities. My very vague modelling estimated that our ‘peak load’ (start of Semester 1) would be in the order of five or six times our demand during our quietest time (Semester 2 mid-semester break), and this was the figure we used to estimate our resourcing levels.
As it turns out, the peak load was closer to nine times the ‘trough load’.
What this translated to was a situation at the start of Semester 1 which bordered on systemic collapse on several occasions. People, systems and space were stretched to their absolute limits, and if any one of those elements had experienced a hiccup in those first couple of weeks then the whole thing would have folded at the very time that students needed us the most. Thanks to the efforts of every person involved, the patience of our students, as much planning as we could muster and a decent dash of luck, we got through.
Tonight’s census didn’t enjoy the same fate.
So peak loads are bad juju, no matter what business you’re in and no matter what resource is going to be stress tested under that load – there’s no rocket science in that. The ABS, unlike Flinders Connect, would have had far more comprehensive data on what to expect in terms of peak load, and in theory their technology partners IBM should have resourced accordingly – lots of cloud this, elastic that and virtualisation yada yada yada. I’ve no doubt they did do all this, and they still failed miserably.
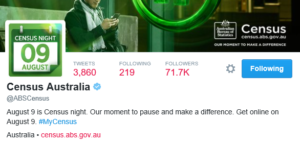 Looking beyond this though makes me think of what appears to be a major blunder by the ABS in not making a far bigger effort to spread that peak load across a much broader timeframe given the potential risk. Looking at the communications sent out by the Census Twitter account in the days leading up to the Census, the entire focus was about a ‘big bang’ event – ‘Get online on August 9’. I can almost hear the voices of the Marketing team at the ABS (sounding like a perfect reincarnation of Rhonda from Utopia) – ‘let’s really try and whip up some buzz around this one, some engagement, let’s make this thing go viral on the 9th…’
Looking beyond this though makes me think of what appears to be a major blunder by the ABS in not making a far bigger effort to spread that peak load across a much broader timeframe given the potential risk. Looking at the communications sent out by the Census Twitter account in the days leading up to the Census, the entire focus was about a ‘big bang’ event – ‘Get online on August 9’. I can almost hear the voices of the Marketing team at the ABS (sounding like a perfect reincarnation of Rhonda from Utopia) – ‘let’s really try and whip up some buzz around this one, some engagement, let’s make this thing go viral on the 9th…’
In the past, when the Census was on paper, this was not an issue, and in fact made perfect sense. What we have seen this year though is that, surprise surprise, a whole lot of people hitting a website all at once can cause a major fail, and a massive public backlash immediately afterwards. It is worth noting that it was only after the website went so spectacularly down that the ABS shared a very important point – that responders actually don’t have to complete the online form until some date in September, several weeks after August 9.
The ABS also failed to encourage responders to complete their response early if they could, which was supported by the system (or at least it looked that way to me before the whole thing crashed). If I had been told that there was a good chance the whole thing would have gone Titanic on the Big Night then I would have filled it out in the 24 hours beforehand, by which time I had a fair idea of who would be staying at my house, what their religion was and what the main functions of their job were (for the record, I entered a cheeky line of ‘reinventing the Higher Education services paradigm’ in that bit for mine, which was of course lost when the site crashed along with the rest of my data). If I had been encouraged to get my act together early, then I would have done so, and I probably wouldn’t be writing this post.
Instead, the whole thing was built up as a Tuesday night extravaganza, the whole country got online at once, and the rest is history. I’m not suggesting that spreading the load would have been a guaranteed prevention of the problems, or that there was no technical work that could have been done to make the platform more robust. My point is that if you can distribute load over a broader timeframe rather than letting – or indeed promoting – it to happen in one massive peak, then you’re lowering the risk of failure of the entire system, no matter what business you’re in.
In this case, the implementation of an online Census by taking the old paper model and simply shifting it online rather than looking at how the process could be improved to spread the load and reduce the risk backfired spectacularly for the ABS, IBM and the Federal government as a whole.
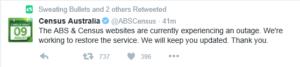 And finally, to rub salt into the wound, was the silence from anyone of significance at the ABS on Census night to take responsibility for the outage, to apologise to responders who had endured frustration and lost data because of the technical failures, and show that there was indeed someone at the helm. The only formal notification I could see anywhere (and I’ll acknowledge here that I don’t watch commercial TV, so I might have missed something there), was an insipid Twitter notification that fell nearly into the category of ‘No Shit, Sherlock’.
And finally, to rub salt into the wound, was the silence from anyone of significance at the ABS on Census night to take responsibility for the outage, to apologise to responders who had endured frustration and lost data because of the technical failures, and show that there was indeed someone at the helm. The only formal notification I could see anywhere (and I’ll acknowledge here that I don’t watch commercial TV, so I might have missed something there), was an insipid Twitter notification that fell nearly into the category of ‘No Shit, Sherlock’.
If anything, this PR nightmare has reminded me of the importance of encouraging, by whatever means available, our students to get organised earlier in the lead up to our peak times and thereby ‘flatten the peak’ of demand, for their sake just as much as ours.